Dear Readers,
with the triumph of LLMs (ChatGPT and Co.), the big question is naturally how to best use AI to optimize my investment decisions. And this includes the question of which AI is actually most suitable and which can do what or what it cannot do. Every artificial intelligence and every tool has its strengths and weaknesses.
The question of which AI is most suitable also includes the question of what I actually want to do. Do I want to discuss scenarios or current assessments? Do I want to research data and facts or a general analysis? How deep do I want to go and how much interpretation do I want to do myself.
The AI: The Eternal Yes-Man
Anyone who asks ChatGPT for stock recommendations often receives impressively formulated answers. But limitations quickly become apparent, e.g. as soon as you ask the AI about something it doesn't know. All models are still very bad at saying what they don't know. When asked about topics outside their area of competence, they therefore answer with the same tone of conviction as when they actually know the answer. This is dangerous because as a user, this is often not recognizable.
___hwr3un4f.png)
Here lies the greatest danger when using artificial intelligence as a companion in investment decisions: hallucination. AIs have a tendency to tell users too much what they want to hear. They absolutely want to satisfy the other person, and that means they would rather make something up than communicate non-knowledge, and they agree with the user very quickly and allow themselves to be convinced by their perspectives. Although the wanting in the machine is of course relative, that's just how it works.
Especially "telling the user what they want to hear" harbors its own dangers, because the user can convey their bias completely subconsciously in linguistic subtleties and thus give the AI their own opinion in the dialogue, so that a drift takes place here that tends to give the user confirmation. This naturally feels dangerously good, but is counterproductive especially in critical analysis. We rather need the critical counterpart who questions us and points out possible errors in thinking.
What the Individual (non) AIs Can Do
Let's look in detail at the major competitors among AI models: ChatGPT, Anthropic Claude, Gemini and Perplexity. What can they do and what can they not do (well)? Small spoiler: For our AI stock analysis at Leeway, we use three of the models in combination so that they mutually resolve each other's weaknesses with their strengths.
ChatGPT-5 (OpenAI)
The latest variant of ChatGPT is sometimes brilliant in logical reasoning. For very complex questions and deep insights in long chains of reasoning, ChatGPT is the best choice among the major chat models. You can, for example, ask which companies in the second tier benefit from the AI boom or from grid expansion in Europe.
Also compared to the subconscious drift I mentioned above, GPT-5 is more resilient than the other models. Nevertheless, there are also problems with GPT-5. For me, one of the most serious is the absolutely unreasonable communication. This is supposed to change soon, but currently the responses from GPT-5 are certainly the most difficult, incomprehensible and unpleasant that exists among AIs. That sounds, for example, like this:
"Note: Not investment advice. Always check balance sheet quality, order backlog, pricing power and project risk sharing (EPC vs. components).
- Cable accessories, connection technology, fittings
-
NKT Photonics/Components: Accessory proximity to HV cable projects (at NKT overall, but focus on components)."
Additionally, it still has significant problems with hallucination and regularly invents inaccuracies, albeit often only small ones. Natively, ChatGPT also has no connection to real-time data and relies on an interface with search functionality. Because of course, and this is also a problem for all AIs, the training corpus is not current and in some cases only goes up to 2023. The AI can only know all developments after that in fragments through current search results, and evaluating the development of over two years based on 20-30 search results is of course like looking through the eye of a needle.
Anthropic Claude
The strengths of Anthropic's models lie in the very pleasant and understandable language and in the resilience against false statements. With logical reasoning and deep analyses, Claude is not quite as good as GPT-5, but the answers are incomparably more understandable and the model is significantly freer in its thinking and conversation paths. Here you can easily work on different levels and illuminate different perspectives. At the same time, Claude amazingly manages to consistently rank first in error resilience in tests.
Bereit für bessere Investment-Entscheidungen?
Starten Sie noch heute mit Ihrer kostenlosen Testphase - Aktienanalyse mit künstlicher Intelligenz.
Volle Transparenz | Voller Zugriff | Jederzeit kündbar
But at the same time, Claude is also the biggest among the yes-men and likes to praise the user as the smartest person of all time. It is sometimes uncomfortable and it is difficult to know whether the idea you just presented is actually coherent or whether the AI just manages to make even the dumbest idea look smart.
Pro Tip: Ask the AI for a "critical analysis" or "its own, unfiltered opinion," either about your own input or also again in relation to a previous answer from the AI.
Perplexity
Perplexity has the great advantage of directly integrating both current news and real-time data and also directly integrates a graphical representation. Although we nevertheless of course have the cutoff of the training data and always only get the small excerpt through the search results currently. Nevertheless, Perplexity is the best choice for very current questions and latest developments.
At the same time, the analyses themselves lag behind the other models in terms of depth and quality. Perplexity cannot compete with Claude or ChatGPT in the logical area and is also susceptible to drift, although of course the deep integration of search creates a certain limitation here. However, the limitation also means that you tend to stay close to the internet consensus, because Perplexity's opinion is dominated by the most prominent search results.
Google Gemini
Gemini scores with integration into the Google ecosystem and access to real-time data, as well as Google Notebook. If you want to analyze quarterly reports or have a spreadsheet compiled, Gemini is a good choice. However, in terms of logic depth and quality of answers, I would prefer Sonnet and ChatGPT.

The Three Systematic Gaps
Using these AI models for stock analysis therefore requires some skill. Because LLMs hallucinate facts when sources are missing or outdated, and even Perplexity doesn't completely solve this. At the same time, we have a consistency problem. Because the AIs contain a random element in order to be able to pursue different answer paths.
But this also means that the same questions lead to different results. And we also unconsciously steer with tiny formulations in which direction an artificial intelligence tends. So without careful control, we always bring our own bias into the discussion and don't have a stable counterpart in the AI, but someone who is only too happy to adopt our opinion.
And finally, AIs are known to have problems with calculations. Errors easily occur here that border on complete nonsense. They can write programs quite well, and if you want to have something calculated with the AI, you would do well to first have it logically design the program and only then, in the second step, have the calculations performed with the program. But overall, it must be said that for clear "true" or "false" answers and backtests, they are the wrong tools. After all, they are Language Models.
How We Integrate AI at Leeway
We have decided on a controlled and dedicated path at Leeway. I am of the opinion that even in the new era of LLMs, the following applies: The right tool for the right job. ChatGPT and Co. are incredibly powerful tools, but they are not optimal for every use case, and where they are applied, they require careful control.
LLMs are ideal for complex tasks, explanations, qualitative analyses. They are like a human analyst you talk to, but who doesn't have their calculations in their head and doesn't have the Excel spreadsheet ready. Absolutely ideal for diffuse questions that require an opinion and not a database.
We use LLMs for our business model analysis and the derived Business Rating. This is a structured LLM analysis according to a modernized Porter framework: business model, competitive dynamics, technological disruption, regulatory and ESG risks. Of course, we are aware of the problems with LLMs mentioned above and work with standardized prompts, built-in fact-checking for currency and reliability, and multiple runs and averages.
For the figures, LLMs are not ideal, as mentioned. Too imprecise, too uncontrollable. That's why we rely on classic machine learning here. Learning, data-based but strictly determined algorithms. They automatically adapt to changes, but with the same input we always get the same result. This is how our Market Fit Rating is created, which evaluates how good the balance sheet and P&L actually are and which key figures are positive or negative for the stock price in the current market.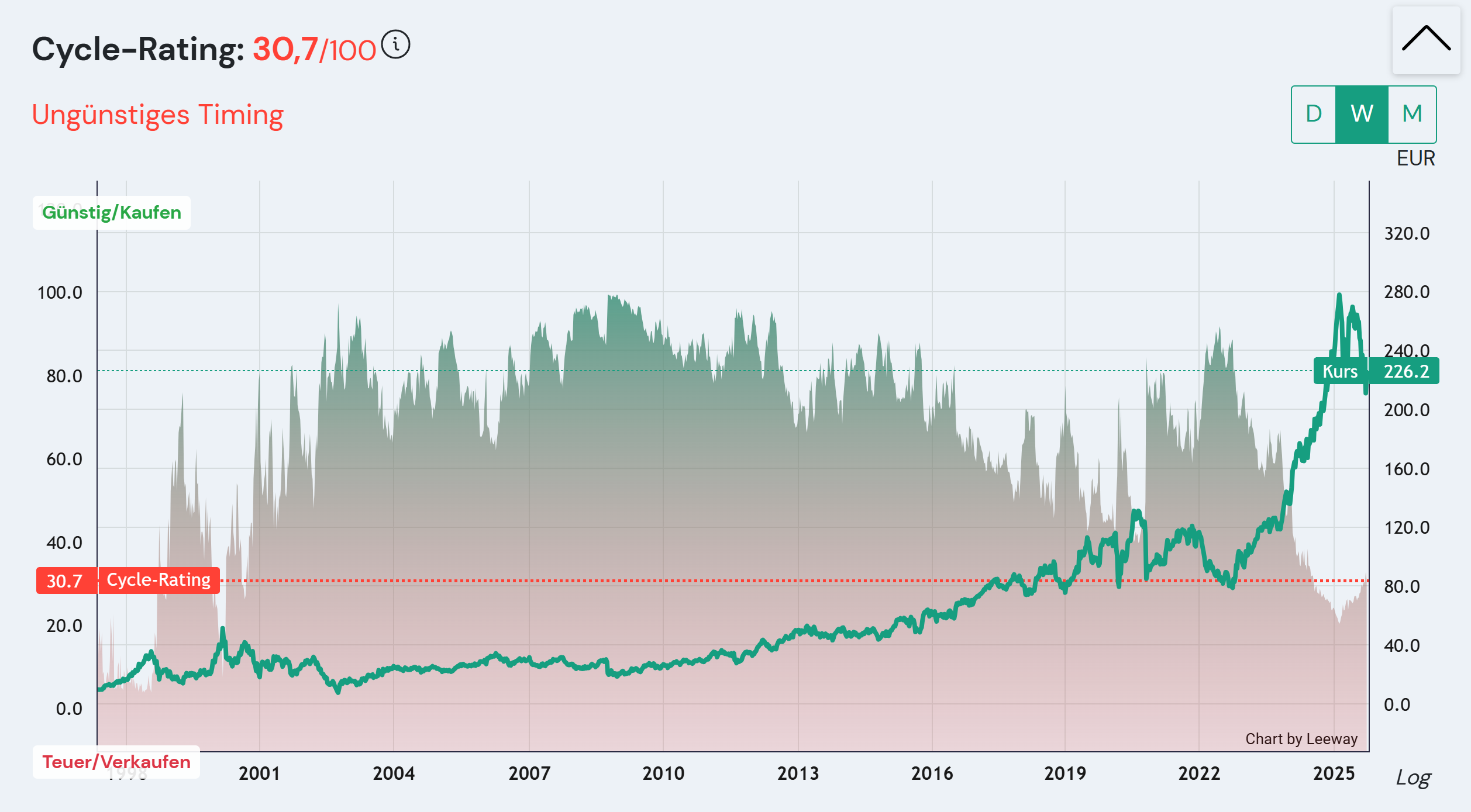
And sometimes you don't need AI at all and a simple calculation with a chart says more than 1000 words of discussion with ChatGPT. For short-term timing with our Cycle Rating, we simply calculate how expensive or cheap a company is based on its own history and display it. It can be that simple.
If you've made it this far, here you can find the best stocks according to the Leeway methodology.
Thank you for reading and good luck!
Lars Wißler